
引言#
在 Oracle DBA 的日常工作中,空间管理是最常见、也最容易被误解的主题之一。
“表空间满了怎么办?”
“删除了大量数据,为什么磁盘空间没变?”
“碎片到底要不要整理?”
这些问题几乎每个 DBA 都会遇到。很多时候,问题不在于不会操作,而在于没有分清不同层级的“空间”到底指什么:是段内空闲、表空间空闲,还是操作系统可见的磁盘空间?
本文将从 Oracle 空间管理的底层架构讲起,系统解释空间分配与回收机制,并结合实际操作场景说明:什么时候该做、什么时候不该做、做了会产生什么影响。目标不是“把空间整理得很漂亮”,而是帮助你做出正确的、面向业务的决策。
第一章:Oracle 空间架构的层次结构#
1.1 四层存储模型#
Oracle 的逻辑存储结构可以分为四层,从宏观到微观依次为:
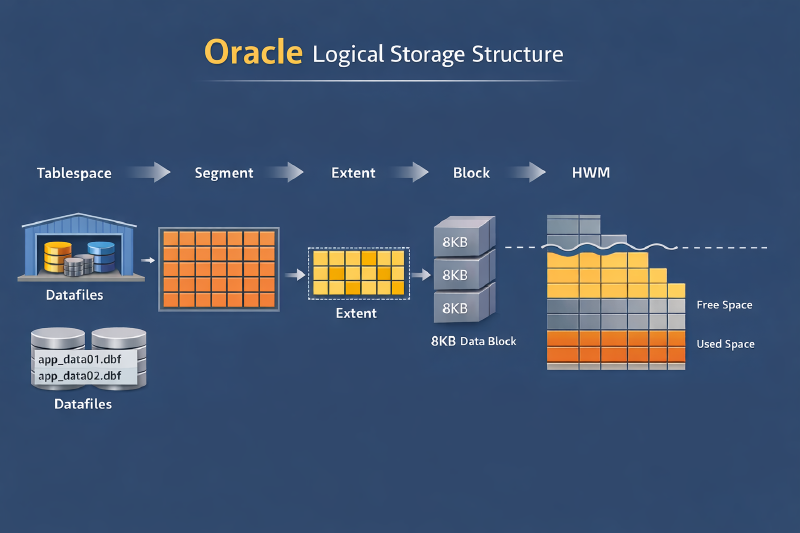
- 表空间(Tablespace):逻辑存储最高层容器,对应一个或多个数据文件。DBA 日常容量管理的主要对象。
- 段(Segment):数据库对象的存储实体。表、索引、LOB 等通常都有独立段。
- 区(Extent):由一组连续数据块组成,是段向表空间申请空间时的分配单位。
- 数据块(Block):Oracle 数据库以数据块(也称为 Oracle 块或页)为单位,来管理数据库数据文件中的逻辑存储空间。数据块是数据库 I/O 的最小单位。
关键点:很多“空间没释放”的争议,都是因为把这四层混在一起看了。
1.2 表空间管理方式的演进:DMT → LMT#
Oracle 表空间管理方式经历了明显演进:
| 管理方式 | 典型时代 | 元数据位置 | 特征 |
|---|---|---|---|
| 字典管理(DMT) | 早期版本 | 数据字典表 | 并发竞争高、易产生管理开销 |
| 本地管理(LMT) | 9i+ 主流/默认 | 数据文件头位图 | 分配效率高、管理开销低 |
| ASSM(段空间管理方式) | 9i+ 主流 | 位图块 | 自动管理块内空闲空间 |
为什么 LMT 显著减少了“表空间碎片”问题?
在 LMT 中,Oracle 通过位图管理区的分配状态,区大小要么是统一大小(UNIFORM),要么由系统自动分配(AUTOALLOCATE)。这使得传统 DMT 时代那种“空闲区难以合并利用”的问题大幅减少。
更准确的说法是:LMT 显著降低了分配管理层面的碎片问题,但段内空闲、HWM 以下空块等“空间现象”仍然存在,只是含义不同。
示例(统一 extents 的 LMT 表空间):
CREATE TABLESPACE app_data_ts
DATAFILE '/u01/app/oracle/oradata/orcl/app_data01.dbf' SIZE 10G
EXTENT MANAGEMENT LOCAL UNIFORM SIZE 1M
SEGMENT SPACE MANAGEMENT AUTO;1.3 段空间管理:MSSM vs ASSM#
MSSM(Manual Segment Space Management)#
通过 Freelist 跟踪可用块,在高并发 INSERT 场景下可能产生热点争用。
ASSM(Automatic Segment Space Management)#
通过位图记录块空间使用状态,显著降低并发争用,是现代 Oracle 的标准配置。
ASSM 常见空闲级别(概念上):
- FS1:0–25% 空闲
- FS2:25–50% 空闲
- FS3:50–75% 空闲
- FS4:75–100% 空闲
- FULL:块已满或低于 PCTFREE 可用阈值
第二章:高水位线(HWM)的本质#
2.1 什么是高水位线?#
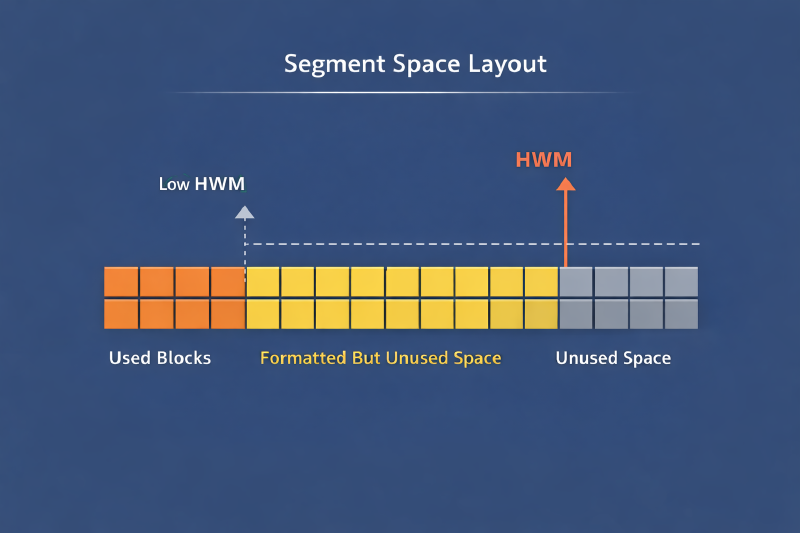
高水位线(HWM)可以理解为:段曾经使用到的最高块位置标记。
即使你删除了大量数据,这些块变成空块,只要 HWM 没下降,Oracle 在某些访问路径(尤其全表扫描)中仍然可能扫描到这些块。
2.2 HWM 为什么影响性能?#
全表扫描(Full Table Scan)通常扫描到 HWM,而不是只扫描“当前有数据的块”。
因此,删除大量数据后你可能会看到:
- 表看起来“行数少了很多”
- 但全表扫描耗时变化不明显
- 段大小也没明显缩小
这并不代表 Oracle “没删掉”,而是因为 DELETE 不会自动降低 HWM。
2.3 关于 HWM 观察的一个常见误区#
很多人会直接看 USER_TABLES.BLOCKS/EMPTY_BLOCKS 判断空间情况,但要注意:
- 这些字段依赖统计信息(stats),不一定实时;
- 在不同版本、不同统计采集方式下,参考价值有限;
- 它们更适合做粗略估算,不是精确诊断。
可先用段大小做快速判断:
SELECT segment_name,
blocks,
ROUND(bytes/1024/1024, 2) AS mb
FROM user_segments
WHERE segment_name = 'MY_TABLE';如果要更精细地分析 ASSM 段内空闲分布,可考虑 DBMS_SPACE(如 SPACE_USAGE、UNUSED_SPACE)做进一步诊断。
示例:适用于:表段 / 索引段(ASSM),能看到每个桶里有多少块(Blocks)。
SET SERVEROUTPUT ON;
DECLARE
l_unformatted_blocks NUMBER;
l_unformatted_bytes NUMBER;
l_fs1_blocks NUMBER; -- 0-25% free
l_fs1_bytes NUMBER;
l_fs2_blocks NUMBER; -- 25-50% free
l_fs2_bytes NUMBER;
l_fs3_blocks NUMBER; -- 50-75% free
l_fs3_bytes NUMBER;
l_fs4_blocks NUMBER; -- 75-100% free
l_fs4_bytes NUMBER;
l_full_blocks NUMBER; -- full blocks
l_full_bytes NUMBER;
BEGIN
DBMS_SPACE.SPACE_USAGE(
segment_owner => 'SCOTT',
segment_name => 'EMP',
segment_type => 'TABLE', -- TABLE / INDEX / CLUSTER / ...
unformatted_blocks => l_unformatted_blocks,
unformatted_bytes => l_unformatted_bytes,
fs1_blocks => l_fs1_blocks,
fs1_bytes => l_fs1_bytes,
fs2_blocks => l_fs2_blocks,
fs2_bytes => l_fs2_bytes,
fs3_blocks => l_fs3_blocks,
fs3_bytes => l_fs3_bytes,
fs4_blocks => l_fs4_blocks,
fs4_bytes => l_fs4_bytes,
full_blocks => l_full_blocks,
full_bytes => l_full_bytes
);
DBMS_OUTPUT.PUT_LINE('Segment: SCOTT.EMP (TABLE)');
DBMS_OUTPUT.PUT_LINE('Unformatted Blocks : ' || l_unformatted_blocks);
DBMS_OUTPUT.PUT_LINE('FS1 (0-25% free) : ' || l_fs1_blocks);
DBMS_OUTPUT.PUT_LINE('FS2 (25-50% free) : ' || l_fs2_blocks);
DBMS_OUTPUT.PUT_LINE('FS3 (50-75% free) : ' || l_fs3_blocks);
DBMS_OUTPUT.PUT_LINE('FS4 (75-100% free) : ' || l_fs4_blocks);
DBMS_OUTPUT.PUT_LINE('Full Blocks : ' || l_full_blocks);
END;
/2.4 关于“碎片”的误解(建议 DBA 必看)#
在现代 Oracle(LMT + ASSM)环境下,很多人说的“碎片”其实不是一回事:
| 概念 | 真实影响 | 是否需要处理 |
|---|---|---|
| 表空间分配碎片(LMT) | 通常较小 | 一般不需要 |
| 段内空闲(HWM 以下) | 可被同段后续重用 | 通常不需要 |
| 行迁移/行链接 | 可能影响访问性能 | 视情况处理 |
| 索引叶块空洞/不平衡 | 部分场景可能有影响 | 证据驱动处理 |
核心原则: DELETE 后产生的段内空闲空间,通常可以被该对象后续 DML 重用。不要仅因为“看起来不整齐”就做重组。
第三章:DELETE / TRUNCATE / DROP 的空间行为对比#
这是空间管理里最常被误解的部分。三者都能“让数据消失”,但空间行为完全不同。
3.1 DELETE:删数据,不降 HWM#
DELETE FROM hr.employees WHERE salary > 30000;空间行为:
- 段内空间:释放为可重用(供该段后续使用)
- 高水位线(HWM):通常不降低
- 表空间可用空间:通常不增加
- 操作系统/ASM 可见空间:不会减少文件大小
- Redo/Undo:大量产生
- 事务特性:可回滚
适用场景:
- 需要按条件精确删除
- 需要回滚能力
- 需要触发器/审计逻辑生效
- 小批量或分批删除(批处理)
实务建议: 大批量删除时,不要一次性删完。建议分批提交,控制 Undo/Redo、归档日志、锁持有时间。
3.2 TRUNCATE:快速清空,重置 HWM#
TRUNCATE TABLE hr.employees;
-- 或
TRUNCATE TABLE hr.employees REUSE STORAGE;空间行为:
- 高水位线(HWM):重置
- 段空间:默认释放多余 extents 给表空间(
DROP STORAGE) - 文件系统/ASM:文件大小通常不变
- Redo/Undo:相对极少(DDL)
- 事务特性:不可回滚(DDL 隐式提交)
两种常见模式:
-- 默认行为(等价于 DROP STORAGE)
TRUNCATE TABLE hr.employees DROP STORAGE;
-- 保留已分配空间,适合马上要重新装载数据
TRUNCATE TABLE hr.employees REUSE STORAGE;适用场景:
- 清空整表(如临时表、阶段表)
- ETL 中间层表重置
- 测试环境快速清空数据
注意:TRUNCATE 不能带 WHERE 条件;且会影响依赖对象/约束场景(需结合外键关系设计)。
3.3 DROP TABLE:删除对象本身#
DROP TABLE hr.employees;
-- 跳过回收站(如果业务允许)
DROP TABLE hr.employees PURGE;空间行为:
- 对象级别:表对象及其依赖对象(索引等)被删除
- 表空间空间:回收(若进入回收站则可能延迟完全释放)
- 文件系统/ASM:文件大小通常不变
- 可恢复性:若进入回收站,可
FLASHBACK TABLE ... TO BEFORE DROP
回收站常用操作:
-- 查看回收站对象
SELECT object_name, original_name, droptime
FROM recyclebin;
-- 恢复
FLASHBACK TABLE hr.employees TO BEFORE DROP;
-- 清空当前用户回收站
PURGE RECYCLEBIN;
-- 清空指定表空间回收站对象(可按需加 USER 子句)
PURGE TABLESPACE users;3.4 三种操作对比总结#
| 操作 | 段内空间重用 | 表空间回收 | 文件系统/ASM 缩小 | HWM | 可回滚 | Redo/Undo |
|---|---|---|---|---|---|---|
| DELETE | ✅ | ❌ | ❌ | ❌ | ✅ | 大 |
| TRUNCATE | ✅(重置后重新分配) | ✅(默认) | ❌ | ✅ | ❌ | 小 |
| DROP | N/A | ✅(回收站可能延迟) | ❌ | N/A | ❌ | 小 |
DROP 本身不可回滚;如进入回收站,可通过 Flashback 恢复对象。
第四章:空间回收的方法与工具#
这一章建议用“按目标层级”来组织,读者最容易理解。
4.1 目标一:释放段空间(降低 HWM / 提高段内利用率)#
方法一:Segment Shrink(推荐优先评估)#
ALTER TABLE hr.employees ENABLE ROW MOVEMENT;
ALTER TABLE hr.employees SHRINK SPACE;
-- 或仅压缩段内数据,不立即降低 HWM
ALTER TABLE hr.employees SHRINK SPACE COMPACT;
-- 连带依赖对象(视版本/对象类型而定)
ALTER TABLE hr.employees SHRINK SPACE CASCADE;优点:
- 通常可在线执行(对业务影响较小)
- 能降低 HWM(非 COMPACT 模式)
注意与限制:
- 仅适用于 ASSM 表空间
- 需要
ROW MOVEMENT - 会改变 ROWID(对依赖 ROWID 的程序要谨慎)
- 某些对象类型/版本存在限制(LOB、IOT、分区对象等要单独确认)
方法二:ALTER TABLE … MOVE(重建段)#
ALTER TABLE hr.employees MOVE;
-- 或移动到新表空间
ALTER TABLE hr.employees MOVE TABLESPACE new_ts;
-- 12c+ 可用在线方式(视版本/对象类型)
ALTER TABLE hr.employees MOVE ONLINE;特点:
- 能有效整理段并重建存储布局
- 常用于迁移表空间、压缩重建
重要注意:
传统 MOVE 后,相关索引通常会变为不可用,需要重建:
ALTER INDEX hr.pk_employees REBUILD;
-- 或在线重建(视版本/许可/对象类型)
ALTER INDEX hr.pk_employees REBUILD ONLINE;方法三:CTAS(适合大改造/结构优化)#
CREATE TABLE hr.employees_new AS
SELECT * FROM hr.employees;
RENAME hr.employees TO hr.employees_old;
RENAME hr.employees_new TO hr.employees;适用场景:
- 需要同时做结构优化(列调整、压缩、分区改造)
- 大表离线重构
- 历史数据治理项目
风险点:
- 索引、约束、权限、触发器、同义词、统计信息需要重建或迁移
- 变更窗口要充分评估
4.2 目标二:释放表空间空闲给操作系统 / ASM(缩小数据文件)#
这是 DBA 常见误区:段里释放了空间 ≠ 数据文件变小。
Oracle 一般不会自动缩小数据文件,若要把空间“还给操作系统/ASM”,需要显式操作。
方法一:收缩数据文件(RESIZE)#
ALTER DATABASE DATAFILE '/u01/app/oracle/oradata/orcl/app_data01.dbf' RESIZE 5G;前提:
- 数据文件尾部没有已分配 extents
- RESIZE 值必须大于文件内最高已用块位置
建议:先评估再收缩(避免 ORA-03297)
- 先确认数据文件 HWM
- 预留增长空间(不要收得太极限)
- 结合 autoextend 策略评估
实务建议:生产库中,宁可保守缩小,也不要频繁“缩了又长”。
方法二:删除空数据文件(特定条件下)#
ALTER TABLESPACE users DROP DATAFILE '/u01/app/oracle/oradata/orcl/users02.dbf';前提:
- 数据文件必须为空(无 extents)
- 版本、表空间类型、管理方式需满足条件
4.3 索引空间管理:Coalesce vs Rebuild#
Coalesce(轻量级整理叶块)#
ALTER INDEX hr.pk_employees COALESCE;- 在线
- 不重建整棵 B-tree
- 适合局部叶块空洞整理
Rebuild(完全重建)#
ALTER INDEX hr.pk_employees REBUILD;
-- 在线(视版本/对象类型)
ALTER INDEX hr.pk_employees REBUILD ONLINE;
-- 压缩重建(视场景)
ALTER INDEX hr.pk_employees REBUILD COMPRESS;经验原则:
- 先问“有没有性能问题”
- 再问“是不是索引导致”
- 最后才决定
COALESCE还是REBUILD
不要因为“删除了很多数据”就习惯性重建索引。
第五章:监控与诊断#
5.1 表空间使用率监控(建议同时看当前值与最大可扩展值)#
你原文的思路是对的,建议在实际使用时再补一列 maxbytes(若开启 autoextend 更有意义),这样不会误判“快满了”。
示例(简化版,按当前分配容量统计):
SELECT
df.tablespace_name,
ROUND(SUM(df.bytes)/1024/1024/1024, 2) AS total_gb,
ROUND((SUM(df.bytes) - NVL(fs.free_bytes,0))/1024/1024/1024, 2) AS used_gb,
ROUND(NVL(fs.free_bytes,0)/1024/1024/1024, 2) AS free_gb,
ROUND((SUM(df.bytes)-NVL(fs.free_bytes,0))/SUM(df.bytes)*100, 2) AS pct_used
FROM dba_data_files df
LEFT JOIN (
SELECT tablespace_name, SUM(bytes) AS free_bytes
FROM dba_free_space
GROUP BY tablespace_name
) fs
ON df.tablespace_name = fs.tablespace_name
GROUP BY df.tablespace_name, fs.free_bytes
ORDER BY pct_used DESC;如果是 OMF/ASM/autoextend 环境,建议再补充
MAXBYTES视角,避免只看当前 bytes。
5.2 大段识别#
SELECT
owner,
segment_name,
segment_type,
ROUND(bytes/1024/1024/1024, 2) AS size_gb
FROM dba_segments
ORDER BY bytes DESC
FETCH FIRST 20 ROWS ONLY;这类 SQL 非常适合做巡检、容量治理、空间回收候选对象筛选。
5.3 表统计信息 vs 段占用空间(“是否值得整理”的初筛)#
SELECT
t.table_name,
t.num_rows,
ROUND(t.blocks * 8 / 1024, 2) AS stats_mb, -- 假设8KB块,仅粗估
ROUND(s.bytes / 1024 / 1024, 2) AS segment_mb,
ROUND((s.bytes / 1024 / 1024) - (t.blocks * 8 / 1024), 2) AS potential_gap_mb
FROM user_tables t
JOIN user_segments s
ON t.table_name = s.segment_name
WHERE s.segment_type = 'TABLE'
ORDER BY potential_gap_mb DESC;注意:
- 这里的
8KB是估算值,实际请按数据库块大小调整; USER_TABLES.BLOCKS依赖统计信息,不是实时值;- 该查询适合做“候选清单”,不适合直接作为 shrink/move 的唯一依据。
5.4 行迁移/行链接检测(建议改写为现代实践)#
- 统计信息:使用
DBMS_STATS - 行迁移/行链接专项诊断:使用
ANALYZE ... LIST CHAINED ROWS
示例:
-- 1) 常规统计信息(推荐)
BEGIN
DBMS_STATS.GATHER_TABLE_STATS(
ownname => 'HR', -- 用户名(Schema 名),替换为你的实际用户名
tabname => 'EMPLOYEES', -- 表名,替换为你的实际表名
method_opt => 'FOR ALL COLUMNS SIZE AUTO', -- 你关注的参数
estimate_percent => DBMS_STATS.AUTO_SAMPLE_SIZE, -- 自动采样比例(推荐)
cascade => TRUE, -- 同时收集索引的统计信息(推荐)
no_invalidate => FALSE -- 使已有的执行计划失效,重新生成最优计划
);
END;
/
-- 2) 链式/迁移行诊断(需预先创建 CHAINED_ROWS 表)
ANALYZE TABLE hr.employees LIST CHAINED ROWS INTO chained_rows;
SELECT COUNT(*) AS chained_row_count
FROM chained_rows
WHERE table_name = 'EMPLOYEES';说明:
CHAIN_CNT的解释和准确性受统计方式影响,实战中更建议把它当作“提示信号”,结合 SQL 性能表现再决定是否处理。
第六章:实战决策建议#
很多文章讲完原理就结束了,但 DBA 真正需要的是“怎么选”。
场景1:删除历史数据后,空间没变,是否要整理?#
先问三件事:
业务是否会很快再写回这些空间? 如果会,通常不需要整理(留着复用更划算)。
是否存在明确性能问题(如 FTS 变慢)? 没有证据就不要动。
你的目标是段内复用、表空间回收,还是 OS/ASM 释放? 目标不同,方法完全不同。
场景2:大表清理后全表扫描变慢#
优先级建议:
- 先确认执行计划是否真在 FTS
- 判断是否因 HWM 过高造成无效扫描
- 再评估
SHRINK/MOVE/ 分区改造
对历史数据治理类大表,长期最优解通常不是反复 shrink,而是分区表 + 生命周期管理。
场景3:磁盘告警,想“立刻释放空间”#
正确路径通常是:
- 找出最大段/增长最快对象
- 确认是否存在可清理对象(临时表、归档、历史分区、回收站)
- 执行对象级回收(如 truncate/drop/shrink/move)
- 最后再评估数据文件
RESIZE
不要一上来就收缩数据文件。
总结#
Oracle 空间管理的核心,不是“把空间变小”,而是准确理解空间所在层级,并选择正确动作。
请记住这五条原则:
- 先分层级:表空间、段、区、块,含义不同,处理方法不同
- 先定目标:是为了性能、复用、回收表空间,还是释放 OS/ASM 空间
- 先看证据:有性能问题再整理,而不是出于“强迫症”整理
- 先控风险:评估事务、锁、ROWID、索引失效、业务窗口
- 长期靠架构:大表历史数据管理优先考虑分区,而不是反复手工回收
数据库管理的目标是服务业务稳定与效率,不是追求“空间看起来完美”。在空间管理上,做正确的事,比做很多事更重要。